En latinoamérica estamos viviendo grandes avances con la implementación de arquitecturas de datos masivos (big data) en organizaciones, y en algunos casos en gobiernos. Pero la necesidad de estrategias efectivas en organizaciones de la sociedad civil, como bomberos y rescatistas, es igualmente grande si no mayor.
Acompañamos en iniciativas y proyectos de ciencia de datos, ingeniería e infraestructura. Visita nuestra página ixpantia y contáctanos.
Contexto
En latinoamérica estamos viviendo grandes avances con la implementación de arquitecturas de datos masivos (big data) en organizaciones, y en algunos casos en gobiernos. Pero la necesidad de estrategias efectivas en organizaciones de la sociedad civil, como bomberos y rescatistas, es igualmente grande si no mayor.
El departamento de estado de los EEUU tiene un programa llamado TechCamp que fue diseñado para crear entornos donde representantes y líderes de la sociedad civil se pueden reunir con expertos para trabajar juntos en entender sus retos y proponer soluciones. Tuve el honor de ser invitado como experto al evento que organizaron del 22 al 24 de setiembre en Tarija, Bolivia para trabajar en los retos de la gestión de riesgos / desastres en la región.
Puntualmente esta región al sur de Bolivia se ve afectada por múltiples incendios forestales cada año. Dan respuesta desde organizaciones de bomberos voluntarios, bomberos profesionales y las fuerzas armadas y aéreas. Esto da a un conjunto de personas muy diversas, con una diversidad de herramientas que tienen a su disponibilidad. Coordinar esto durante un siniestro no es fácil, más si tomamos en cuenta que típicamente estos incendios ocurren en lugares donde no hay red móvil, y mucho menos red de datos. Además hay una necesidad continua para coordinar capacitación, certificación, mantenimiento y reemplazo de equipos y material.

Resultados
Como en todo taller de introducción tomamos un momento para definir lo que es “Big Data”. Personalmente me gusta traducirlo a “datos masivos” para empezar a quitarle algo de misterio y para sugerir a los participantes asegurarse de que están hablando de lo mismo dentro de sus equipos. En vez de frases como “comprar un big data”, o “eso nos lo resuelve big data”, tratamos en grupo de bajarlo a tierra mirando los componentes de una arquitectura de datos masivos. Esto con el propósito de juntos poder identificar los componentes de una posible solución, pero también entender limitaciones.
Después de unas charlas magistrales por los expertos los grupos se dividieron en varios grupos para resolver un reto puntual. El equipo de expertos fué excelente, al estar acompañado por Elfi Herrada (streaming), Mario Cuellar (georeferenciación), y Alejandro Martínez (drones). Pero el trabajo para generar y presentar los proyectos lo hicieron los participantes, quienes lograron dar unas presentaciones impresionantes.
Big Data
El inventario de retos con los participantes en las charlas de introducción al tema de datos masivos dió a una lista que probablemente es reconocible si estás cerca a algún proceso operacional en una organización. Organicé lo que anotamos en el tablero en los siguientes rubros.
Necesidades de soporte en la operación
- Planificación de recursos escasos (personas, material, inventarios)
- Generación de alertas tempranas
- Abrir información / datos al público
- Integrar fuentes diversas de información
- Adecuar capacitación disponible a los de equipos de respuesta
- Capacitación / educación ciudadana
Necesidades en la gestión de información e datos
- Almacenamiento y movimiento de datos para evitar pérdida de información y datos
- Procesos automatizados en hojas de cálculo (Excel)
- Alimentar canales de comunicación con información correcta y actualizada
- Tener información disponible para dar respuesta a eventos súbitos
- Conexión / coordinación de procesos y flujos de información
- Administrar altos volúmenes de datos (ej. grabaciones)
Posibilidades de uso de datos para mejorar procesos
- Alertas tempranas basadas en datos integrados y pronósticos
- Predicción de necesidades con carácter cíclico
- Información centralizada y estandarizada que permite compartir datos entre grupos
- Monitoreo pre/post evento (ej. incendios, desbordes de agua)
- Estadística posterior y lecciones aprendidas para Retroalimentación y manejar historia
- Crear sistemas para dar acceso a datos que permitan comparar y validar
Esto llevó a uno de los grupos a hacer la pregunta: ¿Cómo crear una base de datos central para compartir información entre instituciones? Aquí entraré a más detalle sobre la solución propuesta a esta pregunta puntual, en parte para que sirva de referencia al grupo quienes continúan con el desarrollo de un prototipo.
Arquitectura
Algo que caracteriza el reto es la complejidad y diversidad de fuentes de datos. Y además muchos de estos datos no tienen una fuente sistematizada y oficial. Para poder tener la flexibilidad que necesitamos propusimos usar una arquitectura donde los datos entran a un lago de datos, y con procesos de ETL se procesan para llevarlos a una base de datos. Desde esa base de datos con información limpia y validada alimentamos un tablero, como primer producto de datos.
Buscamos minimizar el costo para la prueba de concepto y me equivoque en decir que hay un programa de Google Cloud que da USD 300,- para gastar en el tiempo de un año. Al revisar, son solo 90 dias pero, el “Free Tier” (nivel de productos gratis) incluye todo lo que necesitamos.
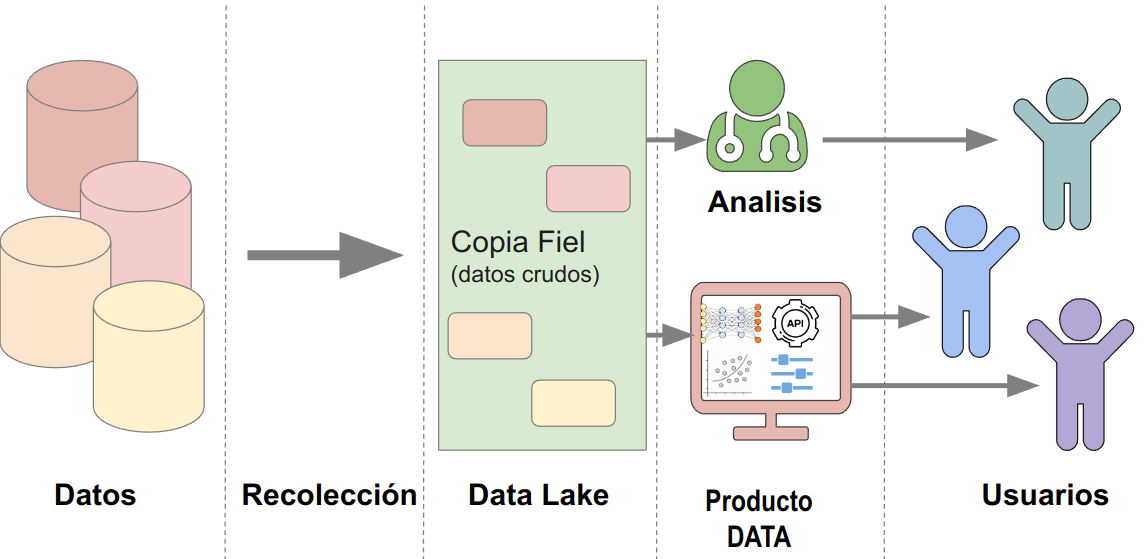
Cloud storage para la ingestión de datos inicial de 5GB Compute Engine para levantar una máquina virtual pequeña en compute engine para montar la base de datos y procesos de procesamiento. Compute engine para hacer un backup diario (snapshots) de la máquina virtual Google Data Studio para conectar con la base de datos y armar el dashboard.
Nota que solamente podemos usar esto libre de costo en regiones us-east1, us-west1, and us-central1
Durante la capacitación usamos un servicio “managed” para levantar una base de datos PostgreSQL. Eso es más fácil, y da la posibilidad de usar infraestructura datos. Pero el costo mínimo rápidamente supera los USD 10,-, lo que lo hace no imposible, pero menos atractivo para una prueba de concepto. Aun así, el presupuesto para la infraestructura de este tipo de iniciativas puede ser bajo. Sube cuando se empieza a usar más, incorporando más datos o más usuarios. Y con eso en el mejor de los casos este incremento de costos puede ir de la mano de incremento de presupuesto.
Resultado
Nos tocó correr para llegar preparados a la presentación, pero con esfuerzo conjunto logramos levantar una infraestructura básica para consumir los datos ejemplo que creamos y hacer un dashboard con interactividad para hacer una demo al resto del grupo. Es lindo ver como los diferentes participantes traen aptitudes a la mesa que en conjunto les permitió diseñar una solución, implementarla, y preparar una presentación mostrando el contexto y alcance de la misma.

Cierre
Participar en un TechCamp es un lujo. La energía de un grupo que viene con problemas de alto impacto en la sociedad, y con mentes abiertas y ganas de trabajar juntos para encontrar nuevas soluciones es contagiosa. Y además es evidencia de que podemos tener mucho impacto y aportar valor en la región latinoamericana con soluciones de datos, aun si son de escala y presupuesto menor.
Links relevantes
Este blog lo mantiene el equipo de ixpantia y la comunidad de gente interesada en datos de la cual estamos contentos de formar parte ¿Tienes una idea para publicar algo aquí? ¡Escríbenos! Estamos siempre interesados en material e ideas nuevas. © 2019-2022 ixpantia



