Actualmente, muchas organizaciones utilizan la computación en la nube para implementar su...
Resumen.
Obtener una solución óptima y rentable en el ámbito de la Ingeniería y Arquitectura de datos en la nube es un proceso que puede resultar complejo. En ixpantia consideramos que el éxito de una solución de este tipo se basa en asegurar procesos robustos de arquitectura, mediante una cultura sólida de experimentación, la adopción de prácticas DevOps y DataOps, la implementación de un sistema de monitoreo de métricas y la utilización de un lenguaje declarativo que facilite la gestión de la infraestructura como código, por ejemplo Terraform.
Experimentación en Ingeniería y Arquitectura de datos
En nuestros proyectos de ciencia de datos, típicamente uno de los pasos iniciales consiste en idear una solución de arquitectura a alto nivel de acuerdo a las necesidades específicas del cliente.
Entre los factores a tomar en cuenta para la concepción inicial de la arquitectura, tenemos por ejemplo la fuente de los datos (si estos provienen desde dispositivos IoT, bases de datos transaccionales, lagos de datos, etc), cuál es el formato de estos datos (XML, json, csv, etc), la frecuencia de llegada de los datos, la plataforma en la nube elegida, los límites de presupuesto, los niveles necesarios de versionamiento de la data, así como las capacidades y el conocimiento de tecnologías y lenguajes por parte de los equipos de ciencia de datos de las empresas a las cuales acompañamos.
Teniendo en cuenta todos estos ingredientes, usualmente llegamos a proponer una arquitectura inicial para el problema en cuestión: una solución que comprende desde las tecnologías propuestas, las soluciones de monitoreo, el costo total aproximado, hasta la definición de acuerdos de servicio para la solución en conjunto con el cliente.
Es importante destacar que el proceso de implementación como tal, debe considerarse desde el inicio como una fase de continua adaptación y mejora. En este contexto, las soluciones de arquitectura e ingeniería de datos, aunque bien fundamentadas y planificadas, pueden requerir ajustes durante la implementación para optimizar su desempeño. Esto se debe a la complejidad inherente de estos sistemas y a factores imprevistos como picos inesperados de carga en el movimiento de los datos, llegada de archivos con formatos corruptos o inesperados, cambios en el entorno tecnológico o en el presupuesto disponible de las empresas, entre otros.
En ixpantia, consideramos que traer la experimentación científica hacia estas disciplinas de carácter más ingenieril es vital para mantener ciclos de innovación de dataductos óptimos, bajos en costo y efectivos. El flujo utilizado lo visualizamos a alto nivel en la siguiente figura:

Figura 1. Flujo durante el desarrollo e implementación de nuestras soluciones de Ingeniería y Arquitectura de datos
Al hablar de acordar, nos referimos a crear los acuerdos de servicio que plasmen las necesidades y los objetivos que debe cumplir nuestra arquitectura. Hacer esto requiere una serie de reuniones con el cliente para poder realizar el inventario de necesidades de la empresa. Esta buena práctica está basada en la Ingeniería de Confiabilidad (SRE, por sus siglas en inglés Site Reliability Engineering). Bajo esta metodología traducimos los requerimientos del cliente en acuerdos de servicio con sus respectivos indicadores y objetivos, entendiendo que los mismos pueden ir evolucionando a lo largo del tiempo.
En cuanto a planear, esto significa procurar los recursos necesarios, tanto tecnológicos como humanos que necesitamos para cumplir el objetivo que tenemos dentro de las restricciones financieras definidas (presupuesto). En este paso, llegamos a una o varias propuestas iniciales, que presentamos al cliente. Nuestro rol acá es acompañarles a tomar una decisión informada a partir de una presentación concisa y completa de la(s) propuesta(s).
Seguidamente, tenemos el nivel de experimentación. Es en esta fase donde proponemos una serie de experimentos con distintas configuraciones para los diversos parámetros que componen nuestra solución. Estos parámetros pueden ser, por ejemplo, número de instancias a utilizar, capacidad de procesamiento requerida (RAM), cantidad de operaciones necesarias en las bases de datos, entre otros.
Por último, llegamos a la fase de evaluación. En este punto recolectamos las métricas de los experimentos realizados, con el fin de determinar y/o proyectar cuáles son las configuraciones más adecuadas para los parámetros que componen nuestra solución, y a la vez, detectar oportunidades de mejoras tanto en desempeño como en costos.
- Nos permite lograr soluciones más costo-efectivas de monitoreo. A menudo, las plataformas en la nube nos ofrecen una amplia gama de herramientas para obtener información de nuestros recursos a nivel granular, sin embargo el uso de estas herramientas puede llegar a consumir una gran parte del presupuesto de las empresas. Experimentar nos permite proponer soluciones alternativas para cumplir las necesidades de monitoreo a costos comparativamente bajos.
- Las tecnologías están en constante evolución. A pesar de que tengamos un conocimiento profundo sobre el funcionamiento de una determinada tecnología en la nube, las empresas deben estar preparadas para adecuarse a los cambios constantes que ocurren en este ámbito. En ocasiones, esto requerirá que los equipos experimenten y se adapten a nuevas funcionalidades a través de un proceso de experimentación durante la ejecución de los proyectos.
- Asegurar la consistencia de los datos es crucial, especialmente cuando estos pueden experimentar transformaciones o serializaciones complejas. Este aspecto es particularmente relevante en el diseño de soluciones para el Internet de las Cosas (IoT), donde se manejan grandes volúmenes de archivos XML o JSON provenientes de sensores. No es raro encontrar archivos con estructuras variables, algunos corruptos o con campos que difieren de lo esperado. Por ello, es esencial llevar a cabo pruebas y experimentación para manejar eficazmente situaciones límite.
- Validar e iterar sobre las arquitecturas propuestas es fundamental. En ocasiones, la diferencia en el uso de dos o más arquitecturas distintas puede inicialmente no parecer significativa para la empresa. No obstante, aún pequeñas diferencias (de pocas decenas de dólares al mes, según la empresa) pueden tener un impacto considerable a largo plazo. Por esta razón la recomendación es evaluar e iterar rápidamente sobre distintas configuraciones posibles para mejorar la rentabilidad.
- Nos permite conocer si algún recurso está siendo sobreutilizado o subutilizado, para determinar dónde y cómo disminuir los costos. Por ejemplo, podríamos identificar mejor cuál es la capacidad de cómputo necesaria de una tecnología serverless como una Function App en Azure, o tal vez podríamos determinar que es factible utilizar una tecnología menos costosa durante el procesamiento mientras ajustamos las especificaciones de una base de datos.
- Identificar la combinación correcta de escalamiento horizontal/vertical de tecnologías serverless es a menudo una tarea complicada, que puede incurrir en costos inesperados o caídas de infraestructura si no se lleva a cabo de manera correcta. Diseñar y llevar a cabo experimentos a pequeña escala nos permite entender mejor las cotas así como el poder de procesamiento mínimo necesario (escalamiento vertical) y número de instancias (escalamiento horizontal) óptimo para procesar adecuadamente un cierto caudal de datos.
- Identificar exactamente el origen y la mejor forma de eliminar cuellos de botella en los dataductos. Las soluciones de arquitectura usualmente conllevan el uso de diferentes tecnologías, tales como emisores o receptores de eventos, bases de datos con límites configurables, soluciones de almacenamiento entre otros que permiten distintas configuraciones las cuales podemos tunear para optimizar el rendimiento, así como los costos.
Características de los experimentos
Las principales características que hemos definido para los experimentos que realizamos son los siguientes:
- Bajo costo: A menudo necesitaremos realizar varias pruebas para encontrar una solución óptima, por esto cada experimento debería representar idealmente un costo bajo.
- Replicables: mantener la historia de los experimentos es crucial para las mejores prácticas de documentación. El uso de terraform, los tags en los recursos, el uso de git y pipelines para CI/CD es de gran ayuda para agilizar los procesos de experimentación.
- Concisos: a menudo las soluciones que estamos desarrollando pueden ser complejas y consistir de una gran cantidad de componentes tales como: múltiples bases de datos, soluciones de almacenamiento, soluciones serverless, virtual machines, emisores y receptores de eventos, entre otros. En el contexto de la experimentación, es crucial disminuir la complejidad de las soluciones que deseamos testear, de manera que podamos discernir adecuadamente cuál es el impacto de ajustar las variables elegidas en los resultados obtenidos.
A más alto nivel, dentro de la experimentación en ingeniería y arquitectura de datos es importante mencionar también los siguientes conceptos en los que basamos la metodología utilizada: DevOps y DataOps, Infraestructura como código, y Monitoreo.
DevOps y DataOps
Las metodologías DevOps y DataOps están siempre reflejadas en las prácticas que utilizamos para desarrollar nuestras experimentaciones. Algunos de los elementos que siempre deben tomarse en cuenta son los siguientes:
- Uso de sistema de configuración de proyectos, tal como AzureDevops, github, ixplorer, entre otros.
- Uso de sistema de control de versiones, en particular git.
- Documentación constante en repositorios.
- Uso de pipelines cuando es posible para la integración y entrega continua de código.
Infraestructura como código (Terraform)
Buena parte de lo que necesitamos hacer al diseñar las soluciones finales específicas para un cliente, tendrá que ver con crear, dar de baja y experimentar con diferentes configuraciones o tipos de recursos. Tomemos, por ejemplo, la necesidad de serializar datos provenientes de un sensor en una solución típica del internet de las cosas (IoT). Esto requiere desarrollar un código, posiblemente en Python, R u otro lenguaje, que permita serializar tipos de archivos como XML o JSON.
Sin embargo, la elección de la tecnología para ejecutar este código constituye una decisión distinta. Podríamos optar por considerar una tecnología serverless, como un Function App en Azure, que vincule la recepción de un archivo a un emisor de eventos para gestionar en tiempo real la cola de archivos. Esta opción podría ser especialmente eficiente para ciertos escenarios. Alternativamente, podría ser adecuado ejecutar el código en una Máquina Virtual en la nube, que procese los datos después de leerlos desde una cuenta de almacenamiento. La elección entre estas tecnologías depende de varios factores, y a menudo será necesario experimentar también distintos enfoques para identificar las soluciones más viables y rentables de acuerdo a las necesidades específicas que se tengan.
Uno de los problemas que puede surgir acá, es que crear y eliminar recursos manualmente puede ser un proceso engorroso y laborioso, involucrando numerosos "clicks" en los portales de las plataformas en la nube, lo que no sólo es tedioso, sino que también limita la trazabilidad de las pruebas. La práctica recomendada es gestionar el código que define la infraestructura como código (IaC) en repositorios separados. Esto reduce significativamente el tiempo en los ciclos de experimentación, optimizando así el proceso de desarrollo.
Para el manejo de la infraestructura como código (IaC), hemos encontrado que Terraform es una herramienta sumamente versátil que nos permite entre otras cosas:
- Consistencia: Al definir la infraestructura en código, los equipos pueden evitar errores de configuración e inconsistencias manuales.
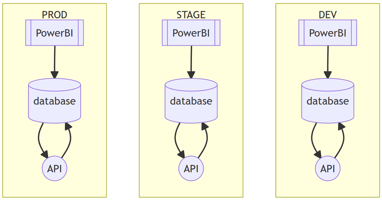
- Reproducibilidad: Es mucho más fácil replicar la infraestructura para diferentes entornos (como desarrollo, staging y producción) cuando la infraestructura está definida en código.
- Control de versiones: permite que los equipos pueden rastrear los cambios a lo largo del tiempo y volver a versiones anteriores si es necesario.
- Automatización: permite a los equipos automatizar la implementación de la infraestructura para distintas especificaciones, lo que reduce significativamente el tiempo y el esfuerzo involucrados.
- Agnóstico de la nube: terraform nos permite definir los recursos como código para distintas plataformas en la nube: desde Azure, GCP y AWS. Una vez entendida la sintaxis, es relativamente sencillo de entender cómo utilizar este lenguaje declarativo para las distintas plataformas existentes.
Monitoreo
En este contexto, una parte imprescindible de un flujo de trabajo basado en la experimentación es el monitoreo (incluido en la fase de Evaluación), pues es la manera en la cual comprobamos nuestras hipótesis, proponemos nuevos experimentos o detectamos puntos de mejora.En cuanto a qué herramientas podemos utilizar para monitorear, dependerá evidentemente de la plataforma de nube en la que estemos trabajando.
Por ejemplo, en Azure contamos con Log Analytics y Application Insights, ambas herramientas capaces de monitorear de manera granular prácticamente cualquier recurso. No obstante, si se utilizan, es altamente aconsejable probarlas en ambientes muy controlados para evitar costos inesperados.
Otra herramienta muy útil en Azure es el Azure Monitor, que nos puede brindar información detallada sobre métricas clave, como por ejemplo el uso de CPU, errores HTTP 404, volumen de archivos recibidos y estadísticas de entrada y salida de datos. Además, Azure Monitor facilita el seguimiento de operaciones de entrada/salida, tanto de escritura como de lectura, entre otros aspectos cruciales para la gestión y optimización del rendimiento de los sistemas.
Como bonus, algunos recursos en Azure cuentan con una sección sobre “Diagnosticar y Resolver Problemas”, que es capaz de brindarnos mucha información no solo sobre potenciales problemas durante el despliegue de las aplicaciones o recursos, si no también acerca del número de ejecuciones, errores, entre otros de acuerdo al recurso monitoreado.
En otras plataformas como GCP y AWS, existen también herramientas específicas para monitorear y evaluar de manera granular el desempeño de nuestros recursos en la nube. En GCP, Cloud Logging y Cloud Monitoring son herramientas esenciales que permiten la recolección y visualización de métricas, logs y eventos en tiempo real, ayudando a resolver e identificar problemas de rendimiento y errores. Por otro lado, en AWS, Cloudwatch es la herramienta principal para monitoreo, ofreciendo capacidades de recopilación de datos y logs, métricas detalladas y alarmas configurables para detectar y evaluar los sistemas de manera proactiva.
Conclusión
En ixpantia, consideramos que la experimentación es un proceso esencial en todas las etapas de desarrollo de las soluciones de ingeniería y arquitectura de datos, desde la concepción, puesta en marcha así como en su tuneo y optimización. Reconocemos que dar este paso puede resultar difícil para muchas empresas, lo que a menudo limita su capacidad para aprovechar al máximo las ventajas de las tecnologías en la nube y desarrollar soluciones cada vez más eficientes y rentables. Sin embargo, creemos firmemente que es un objetivo alcanzable mediante la colaboración y alineación de equipos, la promoción de una cultura de control de versiones y documentación constante, la adopción de la infraestructura como código y el monitoreo constante de los recursos con las tecnologías adecuadas y en ambientes controlados.