This is the second part to the “Your R code probably is 100x slower than it should” blog post. If...
Your R code probably is 100x slower than it should
For the past year or so I have been working on writing performant code out of the box without interrupting my team’s workflow. This way of working, also known as Performance-aware programming (a term coined by Casey Muratori I believe) has enabled us to write better code that wastes less of our valuable time and energy. R packages like orbweaver or tools like faucet are also a result of this mindset.
Applying Performance-aware programming to your everyday way of working should not require writing extensive R packages or CLI tools,
it should not interrupt your usual workflow in any way and it should be easy for other team members to understand and adopt.
In this short article I will be showcasing a very atomic example on how to implement a very simple function and speed up R code almost 100x using your everyday dplyr.
The challenge
While working on a small reporting tool we found the need to translate from ISO months to ISO weeks (according to the ISO 8601 standard). Since calculating these values is non trivial, we initially opted for a simple translation table that we could filter to get our desired answer. (Note that we wanted a function that would work in many places, not just data.frames so just joining the tables wasn’t our first thought).
The table looked like this:
isodates <- tibble::tribble(
~isoyear, ~isomonth, ~isoweek,
2024, 1, 1 ,
2024, 1, 2 ,
2024, 1, 3 ,
2024, 1, 4 ,
2024, 2, 5 ,
2024, 2, 6 ,
2024, 2, 7 ,
# More values here...
2024, 12, 49,
2024, 12, 50,
2024, 12, 51,
2024, 12, 52
)
We then took this dataframe and filtered it according to both year and week.
get_iso_month_r <- function(year, week) {
isodates |>
dplyr::filter(isoyear == year & isoweek == week) |>
dplyr::pull(isomonth)
}
Our naive approach seemed to work. There were some limitations though. Mainly, it wasn’t vectorized. If we wanted to use this in something like dplyr or on an array we would have to use an apply-like function or do rowwise operations. After trying out the following snippet and waiting a while we knew this approach simply wouldn’t work for us.
mock_dataset |>
dplyr::rowwise() |>
dplyr::mutate(isomonth = get_iso_month_r(year, week))Making our code performant
I know what you are thinking, use a case_when statement to vectorize the operation and you are good to go. But my first thought was, if we are going to go through the hassle of writing a case_when statement let’s minimize waste and write it directly in Rust.
So… we wrote our vectorized operation in Rust. At no point did we have to go and write and R package, we simply used the rextendr::rust_function function to write Rust code directly in our R script. This is what it looks like:
rextendr::rust_function(
r"{
fn get_iso_month_rs(years: &[f64], weeks: &[f64]) -> Vec<i32> {
years.into_iter().zip(weeks.into_iter()).map(|(&year, &week)| {
match (year as i32, week as i32) {
(2024, 1..=4 ) => 1,
(2024, 5..=8 ) => 2,
(2024, 9..=13 ) => 3,
(2024, 14..=17) => 4,
(2024, 18..=22) => 5,
(2024, 23..=26) => 6,
(2024, 27..=30) => 7,
(2024, 31..=35) => 8,
(2024, 36..=39) => 9,
(2024, 40..=44) => 10,
(2024, 45..=48) => 11,
(2024, 49..=52) => 12,
_ => panic!("Invalid date")
}
}).collect()
}
}",
profile = "release"
)
These 25 lines of code did exactly what we needed them to do, no more no less. We updated our dplyr pipeline to include our function and everything ran instantly.
mock_dataset |>
dplyr::mutate(isomonth = get_iso_month_rs(year, week))Comparing it to vectorized R
You might still be thinking we could have written this in R with a case_when statement. You are absolutely right. However, the increase in possible is not in order of magnitude, but the decrease in performance is.
As an afterthought for this blog post we wrote the function in R just to see how it performs.
get_iso_month_r_2 <- function(year, week) {
dplyr::case_when(
year == 2024 & week %in% 1:4 ~ 1,
year == 2024 & week %in% 5:8 ~ 2,
year == 2024 & week %in% 9:13 ~ 3,
year == 2024 & week %in% 14:17 ~ 4,
year == 2024 & week %in% 18:22 ~ 5,
year == 2024 & week %in% 23:26 ~ 6,
year == 2024 & week %in% 27:30 ~ 7,
year == 2024 & week %in% 31:35 ~ 8,
year == 2024 & week %in% 36:39 ~ 9,
year == 2024 & week %in% 40:44 ~ 10,
year == 2024 & week %in% 45:48 ~ 11,
year == 2024 & week %in% 49:52 ~ 12
)
}We then created a mock dataset with 100.000 observations to test how our code would perform.
mock_dataset <- data.frame(
year = 2024,
week = round(runif(100000, min = 1, max = 52), 0)
)
microbenchmark::microbenchmark(
times = 100,
"add_isomonth_r_vectorized" = {
mock_dataset |>
dplyr::mutate(isomonth = get_iso_month_r_2(year, week))
},
"add_isomonth_rs" = {
mock_dataset |>
dplyr::mutate(isomonth = get_iso_month_rs(year, week))
}
)
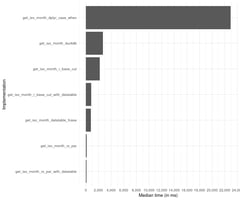
The results were as clear as a summer day. Our R version was about 20 times slower than our Rust function.
Unit: milliseconds
expr min lq mean median uq max neval
add_isomonth_r_vectorized 58.809796 59.765772 72.863495 60.942076 68.028255 198.090077 100
add_isomonth_rs 3.283077 3.527616 3.843486 3.738133 3.844333 6.574269 100We still thought there was a lot of performance on the table. Calling externally linked functions always has some inherent overhead so we increased the mock dataset’s size to 1.000.000 observations. Our Rust code now was 40x faster than our R code.
Unit: milliseconds
expr min lq mean median uq max neval
add_isomonth_r_vectorized 599.49971 825.10239 834.11362 836.73390 844.02839 881.37060 100
add_isomonth_rs 21.52827 21.79659 21.95012 21.86705 21.98735 23.65436 100Just for fun, we added a parallelized version of our Rust function to see how much performance we could get out of this simple function. Adding a single line of code to make the code parallel with the rayon crate was all we needed to create our parallel version of the function.
rextendr::rust_function(
r"{
fn get_iso_month_rs_par(years: &[f64], weeks: &[f64]) -> Vec<i32> {
use rayon::prelude::*;
years.into_par_iter().zip(weeks.into_par_iter()).map(|(&year, &week)| {
match (year as i32, week as i32) {
(2024, 1..=4 ) => 1,
(2024, 5..=8 ) => 2,
(2024, 9..=13 ) => 3,
(2024, 14..=17) => 4,
(2024, 18..=22) => 5,
(2024, 23..=26) => 6,
(2024, 27..=30) => 7,
(2024, 31..=35) => 8,
(2024, 36..=39) => 9,
(2024, 40..=44) => 10,
(2024, 45..=48) => 11,
(2024, 49..=52) => 12,
_ => panic!("Invalid date")
}
}).collect()
}
}",
dependencies = list(rayon = "1.10"),
profile = "release"
)
We ran our benchmarks again (this dev server has 4 vCPUs so take that into account) and the performance kept improving. Now our Rust version was 80x faster than our R version. We are still using dplyr, nothing else about our code changed other than that single function.
Unit: milliseconds
expr min lq mean median uq max neval
add_isomonth_r_vectorized 572.39804 579.536659 637.9863 589.355421 614.49464 1075.81790 100
add_isomonth_rs 21.97963 22.159766 23.5626 22.348087 22.89876 46.58920 100
add_isomonth_rs_par 8.84868 9.014089 10.0714 9.180416 10.07903 20.37571 100Conclusion
Writing performant R code should not be a tedious challenge. Making simple R functions 10x or even 100x faster is possible and should not require a major optimization effort to deliver. In this blog post we showed how a naive Rust (C/C++ applies too) implementation of a function can increase performance with few additional lines of code. When dealing with tasks in Big Data, knowing your toolbelt is essential. A single decision can save millions of CPU cycles and hours of valuable time.
Note: In another blog post we will compare this same implementation to DuckDB and Polars to show that it is not always necessary to switch data frame libraries to achieve high performance in R.